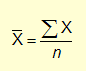
| The mathematical formula looks like this: | |
| Values |
| 4 |
| 5 |
| 6 |
| 7 |
| 8 |
| 9 |
| Values | Tally (frequency) |
| 4 | 1 |
| 5 | 1 |
| 6 | 1 |
| 7 | 3 |
| 8 | 2 |
| 9 | 2 |
| The mathematical formula looks like this: |  |
| X | X-X | (X-X)2 |
| 7 | 7-7=0 | 0X0=0 |
| 5 | 5-7=-2 | -2X-2=4 |
| 8 | 8-7=1 | 1X1=1 |
| 9 | 9-7=2 | 2X2=4 |
| 7 | 7-7=0 | 0X0=0 |
| 6 | 6-7=-1 | -1X-1=1 |
| 9 | 9-7=2 | 2X2=4 |
| 8 | 8-7=1 | 1X1=1 |
| 7 | 7-7=0 | 0X0=0 |
| 4 | 4-7=-3 | -3X-3=9 |
| sum of squared deviations | 24 | |
| sum divided by n-1 (9) | 2.67 | |
| square root (standard deviation) | 1.63 |